Diversity Search
Diversified Recommendation on Graphs: Pitfalls, Measures, and Algorithms
Onur Kucuktunc, Erik Saule, Kamer Kaya, Umit V. Catalyurek
Abstract - Result diversification has gained a lot of attention as a way to answer ambiguous queries and to tackle the redundancy problem in the results. In the last decade, diversification has been applied on or integrated into the process of PageRank- or eigenvector-based methods that run on various graphs, including social networks, collaboration networks in academia, web and product co-purchasing graphs. For these applications, the diversification problem is usually addressed as a bicriteria objective optimization problem of relevance and diversity. However, such an approach is questionable since a query-oblivious diversification algorithm that recommends most of its results without even considering the query may perform the best on these commonly used measures. In this paper, we show the deficiencies of popular evaluation techniques of diversification methods, and investigate multiple relevance and diversity measures to understand whether they have any correlations. Next, we propose a novel measure called expanded relevance which combines both relevance and diversity into a single function in order to measure the coverage of the relevant part of the graph. We also present a new greedy diversification algorithm called BestCoverage, which optimizes the expanded relevance of the result set with (1-1/e)-approximation. With a rigorous experimentation on graphs from various applications, we show that the proposed method is efficient and effective for many use cases.
PDF
diversity, relevance, graph mining, result diversification
Supplementary Material
Set of slides used in the presentation.
λ-Diverse Nearest Neighbors Browsing for Multi-dimensional Data
Onur Kucuktunc, Hakan Ferhatosmanoglu
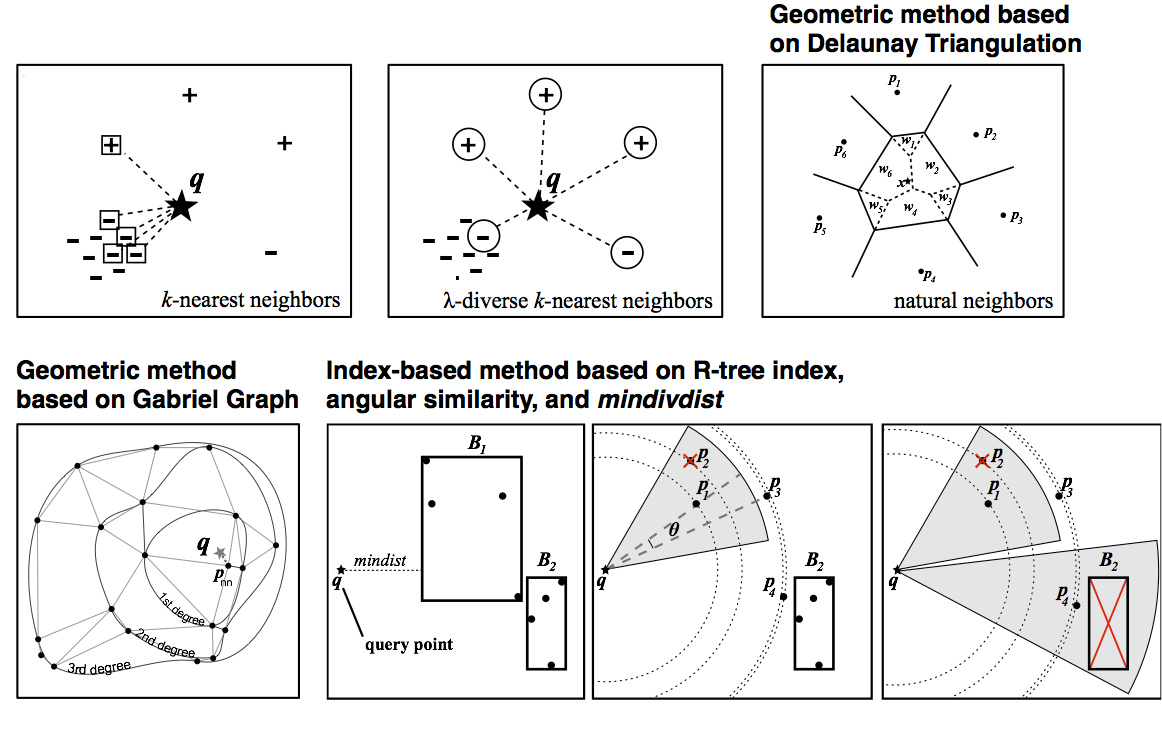
Abstract - Traditional search methods try to obtain the most relevant information and rank it according to the degree of similarity to the queries. Diversity in query results is also preferred by a variety of applications since results very similar to each other cannot capture all aspects of the queried topic. In this work, we focus on the λ-diverse k-nearest neighbor search problem on spatial and multi-dimensional data. Unlike the approach of diversifying query results in a post-processing step, we naturally obtain diverse results with the proposed geometric and index-based methods. We first make an analogy with the concept of natural neighbors and propose a natural neighbor-based method for 2D and 3D data and an incremental browsing algorithm based on Gabriel graphs for higher dimensional spaces. We then introduce a diverse browsing method based on the distance browsing feature of spatial index structures, such as R-trees. The algorithm maintains a priority queue with mindivdist of the objects depending on both relevancy and angular diversity and efficiently prunes non-diverse items and nodes. We experimented with a number of spatial and high-dimensional datasets, including Factual's US points-of-interest dataset with 13M entries. With effective pruning, our diverse browsing method is shown to be more efficient and more effective than KNN and KNDN techniques.
10.1109/TKDE.2011.251
PDF
indexes, nearest neighbor searches, search problems, spatial databases
Supplementary Material
Teaser image prepared for IEEEXplore.